
Project Proposal
Corpus Analysis of Spreadsheet Dependency Structures
Honours project for Daniel Ballinger
Supervisors:
Robert Biddle and
James Noble
robert@mcs.vuw.ac.nz, kjx@mcs.vuw.ac.nz
19 March 2002
Project home page: http://www.mcs.vuw.ac.nz/~elvis/db/honours.html
This document is available online at http://www.mcs.vuw.ac.nz/~elvis/db/proposal.html
Objectives
The objective of this project will be to apply program visualisation techniques to a corpus of spreadsheets to analyse the dependency structures and layout patterns/organisation. More specifically (based on my current understanding or corpus analysis), to investigate styles and approaches of how people program visual spreadsheets, such as Microsoft Excel, to help improve understanding of what makes a high-quality layout. This reason as to why the corpus analysis is carried out will be reviewed as the project is undertaken.
Background context
In recent years there have been several projects relating to the visualisation of visual programs performed by James Noble and Robert Biddle. My project will apply a similar process to the analysis of a large body of spreadsheets.
Based on definitions from [WFE]:
Spreadsheets are a visual programming language designed to perform general computation tasks using spatial relationships rather than time as the primary organising principle. Many programs designed to perform general computation use timing, the ordering of computational steps, as their primary way to organise a program. A well-defined entry point is used to determine the first instructions, and all other instructions must be reachable from that point.
In a spreadsheet, however, a set of cells is defined, with a spatial relation to one another. In the earliest spreadsheets, this arrangement was a simple two-dimensional grid. Over time, the model has been expanded to include a third dimension, and in some cases a series of named grids. The most advanced examples allow inversion and rotation operations that can slice and project the data set in various ways.
It is the spatial relationships or dependencies between cells, both in two and three dimensions that are of interest to visualise. Excel being a visual programming environment, generally has acyclic (can't contain circular references) relationships between cells [DSGPASL] [QCS], which creates a tree like dependency structure (or a forest of trees due to multiple roots). It should be noted that this is not always the case [Refer. Extract from Excel Help File].
Spreadsheets have a wealth of uses in businesses, physical sciences, statistics and many other areas. A good understanding of how people use them could encourage better design, layout, and functionality of spreadsheet programs.
Detailed Specification
Major steps in the project:
- Phase 1 - Creating a program to automate the collection of a corpus of spreadsheets in the Excel format from the Internet.
- Phase 2 - Investigation into the generally accepted guidelines of corpus analysis to increase understanding.
- Phase 3 - Deciding on a visualisation tool suitable (flexible and powerful enough) for creating diagrams with.
- Phase 4 - Finding a format to convert spreadsheets to that will make producing diagrams easier (perhaps XML, dependent on visualisation tool).
- Phase 5 - Creating a series of visualisations that will help reveal interesting properties of spreadsheets.
- Phase 6 - Considering these diagrams, their relative merits and what can be derived from them.
- Phase 7 - Running a few smaller scale runs to see if the diagrams are going to be practical and produce useful information.
- Phase 8 - Do a full scale run to produce completed diagrams using all spreadsheets (categories?).
- Phase 9 - Analysing and interpreting the results of the visualisations and drawing conclusions.
Some of these phases may need to be carried out in parallel, go through several iterations, and be revisited later in the project.
Phase 1 - Acquisition of Spreadsheets
One simple way in which it may be possible to collect the spreadsheets would be to add filetype:xls and num:100 as terms in a search using G o o g l e . This would return a list of links to 100 Excel files. A Download manager like GetRight v4.3 could be given the resulting search page then download and store all the Excel files with no programming required on my part. By choosing appropriate search terms it may be possible to narrow down the search results to those of a particular category. For example, using terms like "Fiscal year", "revenue", and "statement" would mainly produce financial records. I consider this method of collecting spreadsheets valid as how they are collected is not as interesting as their actual contents in terms of this project.
Phase 2 - Research into the principles of Corpus Analysis
Research will be undertaken into the general methodologies of corpus analysis with the intent of looking for generally accepted guidelines. This will involve looking for relevant literature, web pages, and research papers.
Phase 3 & 4 - Visualisation tools and file format
The most suitable style of graphics tool will most likely be vector based with a file format that can be easily produced/read (ASCII). SVG is one possibility that has been used in other honours projects [SVG]. The ability to create three dimensional images using native support from the graphics tool would be a huge advantage.
Phase 5 & 6 - Hypothesis, properties to investigate, and some initial diagram ideas
Data Clustering
Data will exist in large clumps or islands in many spreadsheets and this clustering (pockets of data) of cells should be visible in an analysis of numerous spreadsheets. I suspect that because many spreadsheets would be arranged to facilitate printing that an A4 (paper size) ratio pattern would emerge.
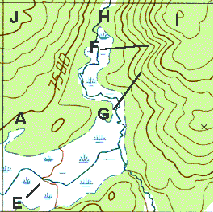
Figure 1: A topographical map with contouring lines.
To show this property I intend to create a diagram based on how many times
each cell is occupied over all the spreadsheets, creating a diagram similar
to the Real Estate Utilisation figure from [VVP].
This could be shown in a diagram analogous to a topographic map with elevation/contour
information. A more ambitious approach would be to create a 3D image. Sectioning
of this contouring map could be used to show distribution of cells in two directions
from the origin.
This diagram could also be applied to different layers of worksheet to examine
layer utilisation.
Analysis of dependency vectors.
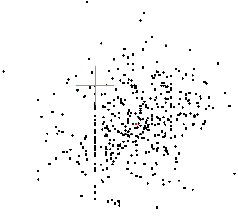
Figure 2: Scatterplot from [PVVP]
The rectangular grid layout of a spreadsheet would cause many of the references
between cells to be vertical or horizontal. Fixed cell references will be one
of the main causes of long vectors and angled vectors.
I suspect that summation will be one of the most common commands, leading to
large clusters of data being referenced by very few cells in many situations.
The principle reason behind this will be syntax for block selections/references
(Ranges) of cells being rectangular in Excel.
The regular patterns used in cell referencing could be an area of interest
in visualising. Like the $ replication command that explicitly encourages this.
Related work has been done by John T. Stasko on execution patterns and by the
IBM Jinsight project about finding patterns with visualisation [IBMJ].
The three dimensional property of many worksheets would show a flow of dependencies between the worksheets. I suspect that most dependencies would flow down from the front sheets towards the lower sheets.
Data flow pipes/valleys and ridges. Creating another diagram similar to the topographical maps again but this time increasing the count on each cell whenever a reference passes through it. I suspect this may create a strong ridging and valley effect. Drawing diagrams that show all the vectors at once with their relative start and finish positions.
It may be possible to create a tree style diagram using the dependency structures of many spreadsheets.
Phase 7, 8 & 9 - Small scale testing, Full scale visualisation production, and Analysis/Conclusions
The final three phases should flow on from the earlier work. It makes sense to do smaller scale testing of the visualisations if they end up being computation intensive.
Limitations of/on the project.
Depending on the number of spreadsheets used a good deal consideration will have to be made as to how to visualise large amounts of data clearly as to allow the derivation of some meaning. Diagrams produced will mainly be of a static nature due to the large volume of information that will need to be displayed (order of thousands of records).The type of data being stored in the worksheets could immensely effect the layout. I'd like to categorise the spreadsheets so it would be possible to compare styles between, say, accounting and scientific sheets.
It may be necessary to limit or crop the size of the spreadsheets as data may stretch out indefinitely. Some consideration will have to be given to the compression and expansion of column width and row height. Ideally any formatting could be ignored (merged cells?) along with the actual value of the cell. Only that the cell is occupied and any references it has to other cells is of interest. Some elements of the spreadsheet may have to be ignored for simplicity, such as tables, links to external documents, macros, embedded images, etc. Any imbedded programs, like Visual Basic for Applications, that allow excel to go beyond normal spreadsheet programming will be excluded, at least initially, from the corpus.
Project Timetable - Plan of Attack
(Dates marked in bold are official deadlines to meet course requirements, other dates are considered as a guide only.)
Some time will also need to be set aside for document production.
Required Resources
Software
- Visualisation tools required (vector based with 3d?)
- Microsoft Excel (More recent version (2000/XP) with XML support.)
- GetRignt Version 4.3
Hardware
- UNIX-based systems as are already provided by the school.
Other
- Sufficient web access, for research purposes.
- Books, etc.
References
[WFE] - Wikipedia (Free Encyclopaedia).
http://www.wikipedia.com/wiki.phtml?title=Spreadsheet
[DSGPASL] Alan G. Yoder, David L. Cohn (2002).
Domain-Specific and General-Purpose Aspects of Spreadsheet Languages, Distributed
Computing Research Lab, University of Notre Dame.
http://www-sal.cs.uiuc.edu/~kamin/dsl/papers/yoder.ps
[QCS] David Chadwick, Brian Knight, Kamalasen Rajalingham (2002).
Quality Control in Spreadsheets: A Visual Approach using Color Codings To Reduce
Errors In Formulae, Information Integrity Research Centre,
School of Computing & Mathematical Sciences, University of Greenwich.
http://www.kamalasen.com/chadwick-00.pdf
[SVG] Matt Duignan (2002).
Matt Duignan's Honours Project page, MCS.
http://www.mcs.vuw.ac.nz/~mduignan/project/
[VVP] James Noble, Robert Biddle. (2001).
Visualising 1,051 Visual Programs - Module Choice and Layout in the Nord Modular
Patch Language, Australian Computer Society, Inc.
http://www.jrpit.flinders.edu.au/confpapers/CRPITV9Noble.pdf
[PVVP] James Noble, Robert Biddle. (August 2001).
Program Visualisation for Visual Programs, Victoria University of Wellington.
http://www.mcs.vuw.ac.nz/comp/Publications/CS-TR-01-6.abs.html
[IBMJ] IBM (2002).
IBM Jinsight , IBM.
http://www.research.ibm.com/jinsight/
Interesting Web References
http://www.mcs.vuw.ac.nz/~elvis/db/reference.html -
Any External document references should be linked from here (requires JavaScript).
http://www.mcs.vuw.ac.nz/~elvis/db/hfiles/circular_ref.txt
- Extract from Excel Help File.
http://www.mcs.vuw.ac.nz/~elvis/db/calendar.html - Calendar
of relevant dates.
Back to Honours Page